
The more customer support reps and conversations you have to oversee, the harder it is to get insights into the quality of all your customer interactions.
Sounds familiar?
Conversation reviews — a customer service quality assurance process for customer support — can make things easier for you.
What are customer service conversation reviews?
Conversation reviews are meant to assess how well your agents’ responses meet your quality standards. By monitoring and scoring all your customer interactions, you can identify and overcome your support weaknesses in the long run. You might’ve also heard about customer service quality assurance, support QA, or ticket reviews — essentially, these are all the same concepts.
Just like with code reviews for software engineers or editorial reviews for writers, the goal of customer service reviews is to have an extra pair of eyes to read and provide feedback for improvements.
Reviews can vary by:
- Type: peer-to-peer reviews, manager reviews, QA agent reviews, self-reviews;
- Frequency: daily, weekly, monthly;
- Breadth: how many interactions are reviewed of total ticket volume;
- Complexity: informal verbal reviews, written reviews, using spreadsheets, or purpose-built software.

Why should you review customer service conversations?
Conversation reviews are the most efficient means of improving your support quality. Internal assessments pinpoint your team’s areas of growth and, with constant feedback, help your agents become better at what they do.
Here are the main benefits of including conversation reviews in your support QA process:
- Take control over your support quality. Find your team’s knowledge gaps and provide actionable feedback that helps your customer service agents improve their performance;
- Bring consistency into your support interactions. Analyze your team’s conversations across all support channels to make sure that everyone can experience exceptional customer service, regardless of who handles the ticket;
- Track and report on your team’s progress. Conversation reviews allow you to keep an eye on your Internal Quality Score (IQS) and notice any changes in your support quality that need your immediate attention.
Now, let’s dive into three major motivations for doing conversation reviews.
![]()
Combat the “meh” feeling about team performance
One of the most common drivers for a support QA process is an overarching feeling that support is performing OK, but it’s not impressive. It’s definitely not the type of customer service that could drive revenue for your business.
This is the easiest, but, in a way, also the trickiest issue to tackle. To make support truly amazing, you first have to articulate what “amazing customer service” means for you specifically. Once you have done that, you can formulate review questions around it.
In other words, you can only succeed if you know what you are trying to achieve. So, take a moment to completely understand what issues you are solving. Then use this knowledge as the foundation for reaching your goals.
Here are some ideas for the questions and categories to track in your reviews:
- Did the customer service representative go above and beyond?
- Did the agent anticipate customer needs/next questions?
- Did they show empathy and used positive language?
- Did the team member merely answer using a customer service script or provide a solution?
- Was the answer outstanding in any respect?

Tackle your team’s inconsistencies
If your team is growing rapidly, you won’t always have consistent quality in your interactions. It’s natural to have some agents who know everything there is to know, and newly-hired customer service representatives who are not able to handle certain tickets just yet.
The experience doesn’t really matter here, though. Assessing the quality of interactions is equally important with agents who’ve been at it for years and assume that their knowledge is up to date, even when it isn’t. Incorrect replies that are delivered with a lot of misplaced confidence will have a negative impact on the quality of your support and “create” frustrated customers.
Here are some ideas for the questions and categories to track in your conversation reviews:
- Did the agent provide adequate information?
- Did the answers reflect up-to-date product knowledge?
- Was the provided solution in line with internal agreements?

Gain insight into your customer service metrics
Conversation reviews provide accurate insight into how well your support team is performing. While customer-based metrics like CSAT, CES, and NPS reflect how satisfied your customers are with your product and services, IQS — the main metric of conversation reviews — gives you an internal perspective on the quality of your support.
In the past years, industry-leading customer service teams like Automattic and Geckoboard have grown to love conversation reviews that increase the quality of their interactions. Now, systematic internal feedback is gaining ground in other customer-facing teams, too.
Use a metric that does not max out at 100% and provides you more insight into your CSAT scores. You and your team are best positioned to determine what are the things that could make each reply even better.
Here are some ideas for the questions and categories to track in your reviews:
- Were the replies timely?
- Was there anything obvious that could have been done better?
- Did the agent do everything in his/her power to solve the case?
- Was this a great example of empathy displayed toward the customer?

How many customer conversations should you review?
The number of customer service reviews you should conduct is dependent on several variables. The volume of total support tickets and the capacity of your reviewer/s are deciding factors.
As a general guideline, most companies aim to review between 2% – 10% of their total ticket volume. Although some companies review much more, some review less. For example, PandaDoc’s customer service strategy includes reviewing almost all tickets during specific periods, e.g. for new employees as part of their onboarding process.
If you’re not sure which amount is right for you, don’t leave it up to fate to decide. You have several options:
- Set a percentage goal. If your goal is an overview of team performance then 10% of your total volume is a nice sweet spot. This gives you a good outline of common problems, covering all agents.
- Set a ticket goal per support rep. If your goal is more focused on fine-tuning your coaching, aim instead to review a certain number of tickets per agent. For example, 5 tickets per agent, per week.
- Set a ticket goal per reviewer. This is useful for peer reviews or managerial reviews. A target of a certain number of tickets, e.g. 10 per week, ensures that your review program is steady and everyone is sharing the responsibility.
Which customer conversations should you review?
What you review matters as much as how much you review.
Many teams simply choose to review at random – it seems to be a logical way of reviewing that provides an accurate sample of your help desk interactions. But random does not give you diversity.
And when you’re reviewing customer service interactions, the outlier interactions are the most valuable, not ones that sit in the average.
Focus on the conversations that matter. The conversations that are most important to review include:
- Longer interactions. In conversations that have more back-and-forth between the customer and support rep, the problem clearly isn’t clean-cut. Dig into problem areas by sifting out the simpler dialogues and spending time on the lengthier ones.
- More complex interactions. Maybe the conversation has passed through a couple of support reps, or there wasn’t just one issue at stake. Review these tickets to understand how to streamline processes or find weaker links in your team.
- Interactions where the customer was dissatisfied. There’s no easy way to say it – sometimes the customer is just not happy. Conversations with a low CSAT rating help you understand what is going wrong and how to improve for next time.
Luckily, Zendesk QA (formerly Klaus) can do the heavy lifting when it comes to conversation sampling.
✨ Spotlight is a unique conversation discovery feature that samples and highlights the conversations critical for your company to review.

How to start reviewing conversations?
We’ve put together a support QA checklist to get your conversation reviews underway:
1. Understand your motivation and the problems you want to address. For example, are you worried about your CSAT, negative feedback, or new agent onboarding?
2. Define your ideal outcome of the review process. Would you like to make sure all agents have up-to-date product knowledge, or that they display empathy in every customer interaction?
3. Create a QA scorecard. Based on your motivation, support stream, and customer service goals, what are the rating categories that will matter to your team?
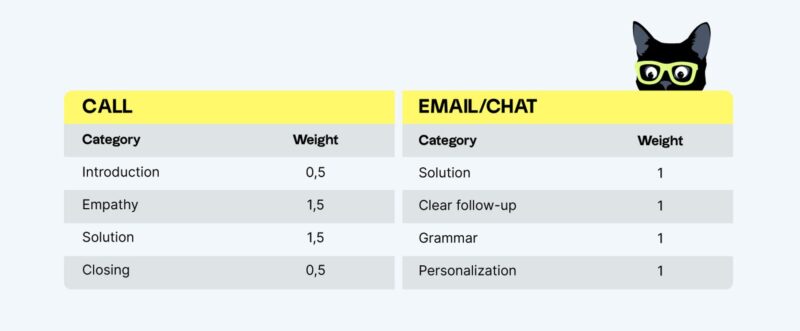
4. Decide who will do conversation reviews:
- Self-review can be an option for smaller customer support teams;
- Peer-to-peer ticket reviews work well in medium-sized companies;
- A full-time person dedicated to ticket review is a common practice in large companies.
5. Use the right tool to track reviewers and reviews. This can be a simple Google Sheet, or a more specialized quality assurance solution like Zendesk QA.
6. Document the conversation review process and communicate it to the team. Put extra effort into talking review processes through with all the involved parties. Make sure that everyone is on the same page on why you’re doing this and how it will help the business.
7. Launch, test, and iterate the process. See what works and what doesn’t. Iterate as your organization and team change.
Why choose dedicated QA software for conversation reviews?
As your company grows and your needs change, you’ll see that spreadsheets become less and less efficient for the purpose. Most teams review hundreds of conversations every month and they want to see information like ticket numbers, URLs, names, dates, and times for each of those interactions in the spreadsheet.
If it takes too much time and manual work, and nobody enjoys the process, then the quality of the feedback will suffer. That’s when dedicated conversation review tools come in handy.

With Zendesk QA, you can identify gaps in your customer experience before they become a problem:
- Use Artificial Intelligence to pinpoint where agents are falling short and resources are going to waste – then fix what isn’t working;
- Automate quality management and achieve 100% coverage across support reps, teams, BPOs, and languages;
- Collect more customer feedback through a fully customizable AI-powered CSAT survey solution.
Addressing customer issues early on is critical for customer satisfaction and customer loyalty. Optimize your support to attract & retain loyal customers!
Originally published in January 2019; last updated in March 2023.

